

What is a XPath?
A XPath can be characterized as a question language utilized for exploring through the XML records so as to find various components. The essential language structure of a XPath articulation is-
//tag[@attributeName='attributeValues']
Presently, we should comprehend the various components in the Xpath articulation language structure – tag, property and trait esteems utilizing a model. Consider the underneath picture of the Google site page with Firebug reviewing the Search-bar div.
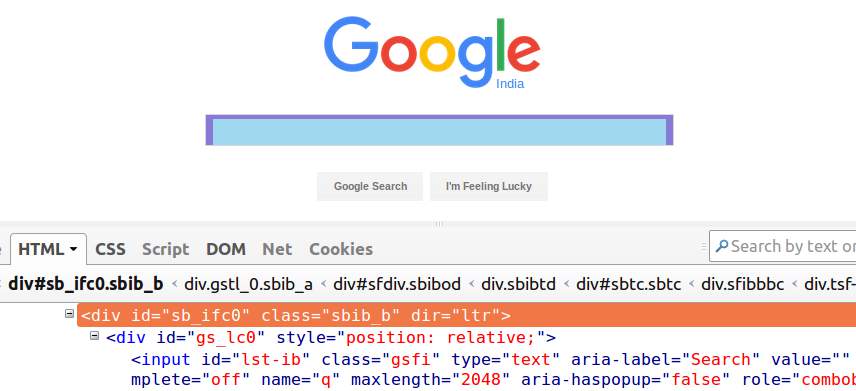
- '/' or '//' – The single slice and twofold cut are utilized to make outright and relative XPaths(explained later in this instructional exercise). Single slice is utilized to begin the determination from root hub. While, the twofold cut is utilized to get the present hub coordinating the choice. For the present, we will utilize '//' here.
- Tag – Tags in HTML start with '<' and end with '>'. These are utilized to encase various components and give data about the handling of the components. In the above picture, 'div' and 'input' are labels.
- Property – Attributes characterize the properties that the HTML components hold. In the above picture, id, classes, and dir are the characteristics of the external div.
- AttrbuteValue – AttributeValues as the name propose, are the estimations of the characteristics for example 'sb_ifc0' is the property estimation of 'id'.
Utilizing the XPath sentence structure showed above, we can make numerous XPath articulations for the google searchbar-div given in the picture like/div[@id='sb_ifc0′],/div[@class='sbib_b'] or/div[@dir='ltr']. Any of these articulations can be utilized to get the ideal component as long as the qualities picked are novel.
What are the different types of XPath?
There are two sorts of XPath articulations
- AbsoluteXPath – The XPath articulations made utilizing outright XPaths starts the determination from the root hub. These articulations either start with the '/' or the root hub and cross the entire DOM to arrive at the component.
- Relative XPath – The relative XPath articulations are much progressively conservative and use forward twofold slices '//'. These XPaths can choose the components at any area that coordinates the choice standards and doesn't really start with the root hub.
Thus, which one of the two is better?- The relative XPaths are viewed as better in light of the fact that these articulations are simpler to peruse and make; and furthermore progressively hearty. The issue with outright XPaths is, even a slight change in the DOM from the way of the root hub to the ideal component can make the XPath invalid.
Finding Dynamic Elements using XPaths
Numerous multiple times in robotization, we either don't have interesting qualities of the components that exceptionally recognize them or the components are progressively produced with the property's estimation not known previously. For cases like these, XPath give various techniques for finding components like – utilizing the content composed over the components; utilizing component's record; utilizing somewhat coordinating characteristic worth; by moving to kin, youngster or parent of a component which can be extraordinarily distinguished and so forth.
Using text()
Using text(), we can locate an element based on the text written over it e.g. XPath for the ‘GoogleSearch’ button –
//*[text()=’Google Search’](we used ‘*’ here to match any tag with the desired text)
Using contains()
The contains(), we can coordinate even the estimations of the somewhat coordinating qualities. This is especially useful for finding dynamic qualities whose some part stays steady for example XPath for the external div in the above picture having id as 'sb_ifc0' can be found even with halfway id-'sb' utilizing contains() –//div[contains(@id,’sb’)]
Using element’s index
By giving the record position in the square sections, we can move to the nth component fulfilling the condition for example /div[@id='elementid']/input[4] will get the fourth information component inside the div component.
Using XPath axes
XPath tomahawks help in finding complex web components by navigating them through a kin, kid or parent of different components that can be distinguished without any problem. A portion of the generally utilized tomahawks are-
- child– To choose the kid hubs of the reference hub. Linguistic structure – XpathForReferenceNode/child::tag
- parent–To choose the parent hub of the reference hub. Sentence structure – XpathForReferenceNode/parent::tag
- following– To choose all the hubs that come after the reference hub. Language structure – XpathForReferenceNode/following::tag
- preceding To choose all the hubs that precede the reference hub. Linguistic structure – XpathForReferenceNode/preceding::tag
- ancestor– To choose all the progenitorcomponents before the reference hub. Sentence structure – XpathForReferenceNode/ancestor::tag







