Calculated Regression alludes to the AI calculation that is utilized to anticipate the likelihood of absolute ward variable. In strategic relapse, the needy variable is parallel variable, which comprises of information coded as 1 (Boolean estimations of genuine and bogus).
Right now, will concentrate on building up a relapse model in Python utilizing ceaseless variable. The model for straight relapse model will concentrate on information investigation from CSV record.
The grouping objective is to anticipate whether the customer will buy in (1/0) to a term store.
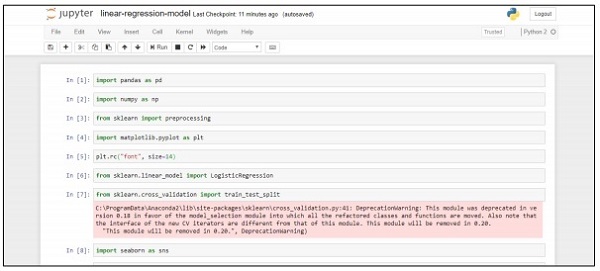
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
import seaborn as sns
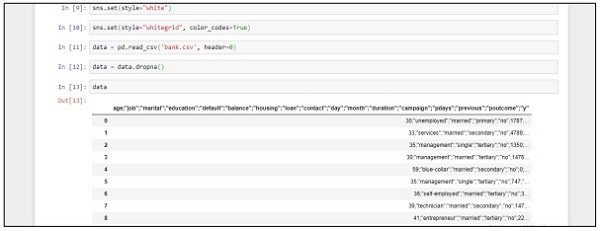
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
data = pd.read_csv('bank.csv', header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))
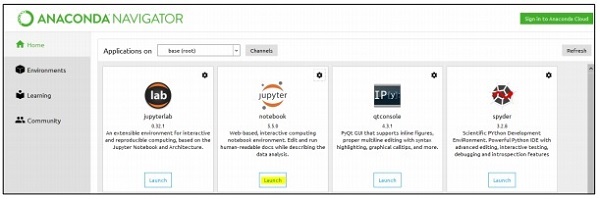
Follow these means to execute the above code in Anaconda Navigator with "Jupyter Notebook" −
Step 1 − Launch the Jupyter Notebook with Anaconda Navigator.
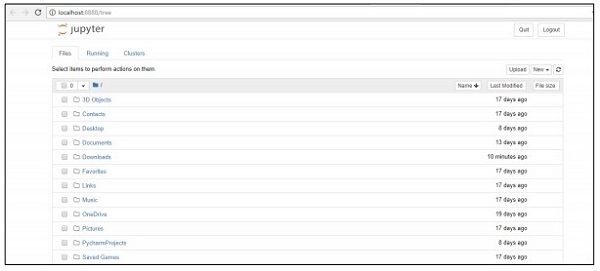
Step 2 - Upload the csv record to get the yield of relapse model in orderly way.
Step 3 − Create another document and execute the previously mentioned code line to get the ideal yield.