Information representation assumes a significant job in information science. We can consider information representation as a module of information science. Information Science incorporates more than building prescient models. It incorporates clarification of models and utilizing them to get information and decide. Information perception is a basic piece of introducing information in the most persuading manner.
From the information science perspective, information representation is a featuring highlight which shows the progressions and patterns.
Consider the accompanying rules for successful information perception −
- Position information along normal scale.
- Utilization of bars are progressively powerful in correlation of circles and squares.
- Appropriate shading ought to be utilized for dissipate plots.
- Use pie outline to show extents.
- Sunburst perception is progressively viable for various leveled plots.
Lithe requirements a straightforward scripting language for information perception and with information science in coordinated effort "Python" is the recommended language for information representation.
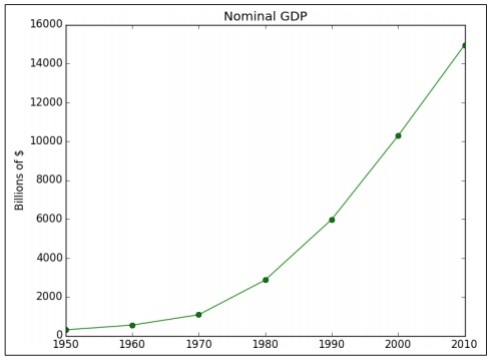
Example 1
The accompanying model exhibits information representation of GDP determined in explicit years. "Matplotlib" is the best library for information perception in Python. The establishment of this library is appeared underneath −
Consider the accompanying code to comprehend this −
import matplotlib.pyplot as plt
years = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
gdp = [300.2, 543.3, 1075.9, 2862.5, 5979.6, 10289.7, 14958.3]
# create a line chart, years on x-axis, gdp on y-axis
plt.plot(years, gdp, color='green', marker='o', linestyle='solid')
# add a title plt.title("Nominal GDP")
# add a label to the y-axis
plt.ylabel("Billions of $")
plt.show()
Output
The above code creates the accompanying yield −
There are numerous approaches to modify the graphs with pivot names, line styles and point markers. How about we center around the following model which exhibits the better information perception. These outcomes can be utilized for better yield.
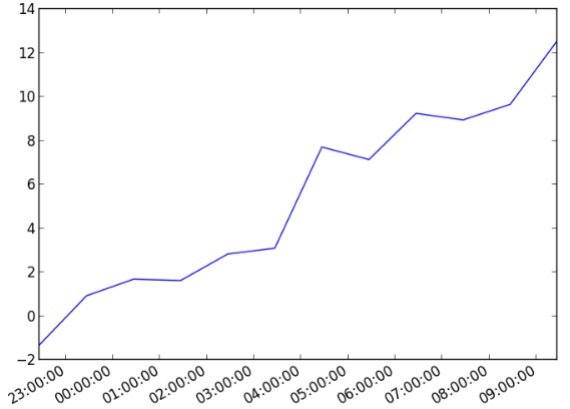
Example 2
import datetime
import random
import matplotlib.pyplot as plt
# make up some data
x = [datetime.datetime.now() + datetime.timedelta(hours=i) for i in range(12)]
y = [i+random.gauss(0,1) for i,_ in enumerate(x)]
# plot
plt.plot(x,y)
# beautify the x-labels
plt.gcf().autofmt_xdate()
plt.show()
Output
The above code produces the accompanying yield −