

Data in MongoDB has a flexible schema.Documents within the same collection. They do now not want to have the equal set of fields or structure Common fields in a collection’s documents can also hold exclusive forms of information.
Data Model Design
MongoDB offers two sorts of facts fashions: — Embedded information version and Normalized facts version. Based at the requirement, you could use both of the models even as making ready your document.
Embedded Data Model
In this model, you can have (embed) all the associated facts in a unmarried report, it is also referred to as de-normalized records version.
For instance, assume we are becoming the info of employees in three one of a kind files specifically, Personal_details, Contact and, Address, you may embed all of the 3 files in a single one as proven beneath −
{
_id: ,
Emp_ID: "10025AE336"
Personal_details:{
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
},
Contact: {
e-mail: "radhika_sharma.123@gmail.com",
phone: "9848022338"
},
Address: {
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}
}
Normalized Data Model
In this model, you may refer the sub files within the unique file, using references. For instance, you may re-write the above report within the normalized model as:
Employee:
{
_id: <ObjectId101>,
Emp_ID: "10025AE336"
}
Personal_details:
{
_id: <ObjectId102>,
empDocID: " ObjectId101",
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
}
Contact:
{
_id: <ObjectId103>,
empDocID: " ObjectId101",
e-mail: "radhika_sharma.123@gmail.com",
phone: "9848022338"
}
Address:
{
_id: <ObjectId104>,
empDocID: " ObjectId101",
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}
Considerations whilst designing Schema in MongoDB
- Design your schema in line with user necessities.
- Combine gadgets into one report if you may use them together. Otherwise separate them (but ensure there ought to now not be want of joins).
- Duplicate the information (however limited) because disk area is reasonably-priced as examine to compute time.
- Do joins while write, no longer on read.
- Optimize your schema for most frequent use cases.
- Do complicated aggregation within the schema.
Example
Suppose a consumer needs a database design for his weblog/website and notice the variations between RDBMS and MongoDB schema layout. Website has the subsequent requirements.
- Every put up has the particular title, description and url.
- Every submit will have one or greater tags.
- Every publish has the call of its writer and total number of likes.
- Every publish has feedback given by means of customers along side their name, message, statistics-time and likes.
- On each submit, there can be 0 or extra feedback.
In RDBMS schema, design for above requirements could have minimal 3 tables.
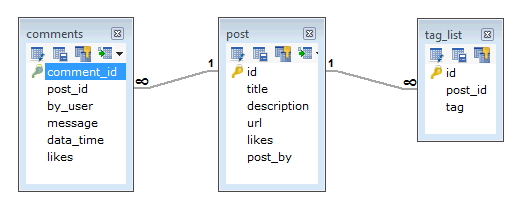
While in MongoDB schema, design can have one collection publish and the following structure −
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}
So at the same time as showing the records, in RDBMS you need to sign up for 3 tables and in MongoDB, facts might be shown from one series simplest.







